
Latxa: An Open Language Model and Evaluation Suite for Basque
We are glad to announce a new step in our effort to build Large Language Models (LLMs) and evaluation suites that enable reproducible research on building LLMs for Basque and other low-resource languages, as described in a new paper (https://arxiv.org/abs/2403.20266).
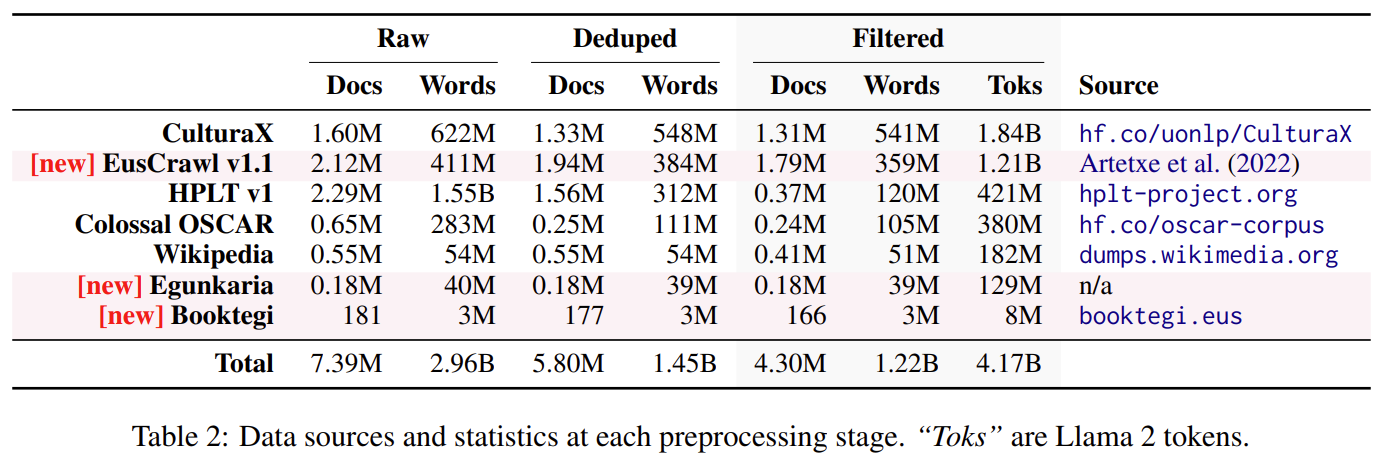
The paper introduces a new version of Latxa, a family of large language models for Basque ranging from 7 to 70 billion parameters. Latxa is based on Llama 2, which we continue pretraining on a new Basque corpus comprising 4.3M documents and 4.2B tokens. This new corpus is the largest available for Basque (more than double the size of predecessors), and combines various existing datasets, as well as some new ones that we release with this work. We have prioritized quality over quantity when constructing our corpus, prioritizing high-quality data sources and applying a thorough deduplication and filtering process.
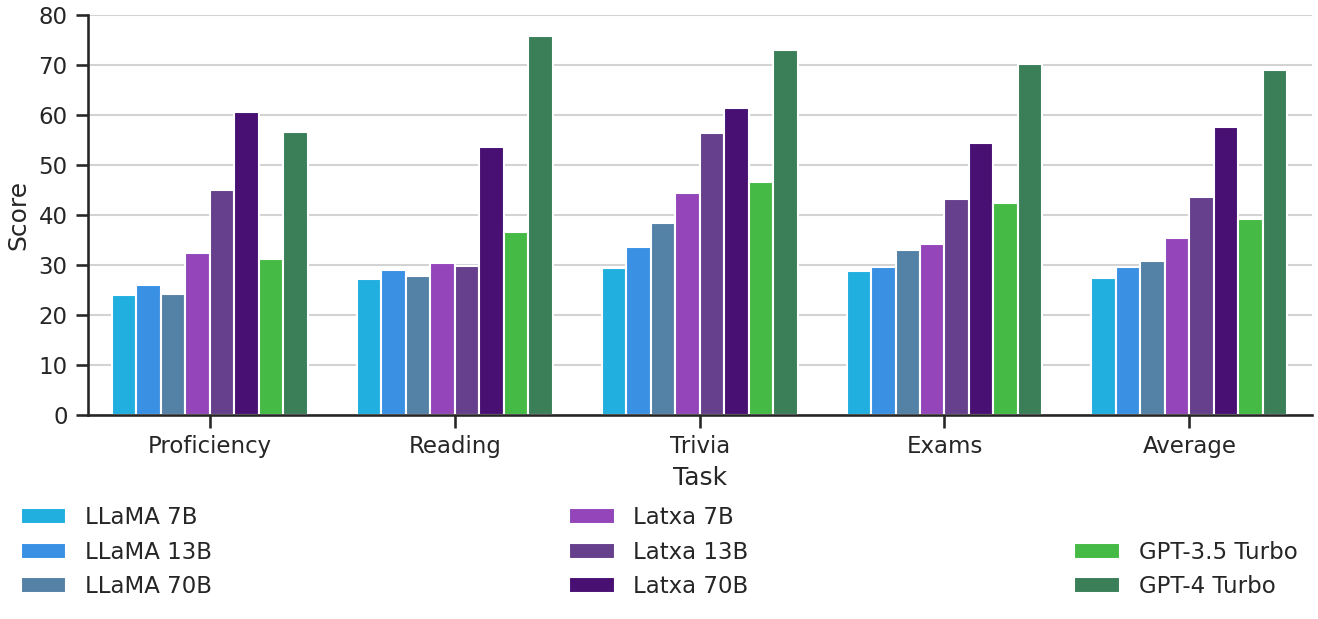
Addressing the scarcity of high-quality benchmarks for Basque, we further introduce four multiple choice evaluation datasets: EusProficiency, comprising 5,169 questions from official language proficiency exams; EusReading, comprising 352 reading comprehension questions; EusTrivia, comprising 1,715 trivia questions from 5 knowledge areas; and EusExams, comprising 16,774 questions from public examinations.
In our extensive evaluation, Latxa performs substantially better than all existing open models, including Llama 2. It is also superior to GPT-3.5 Turbo in all datasets we evaluate on. Interestingly, our best model also outperforms GPT-4 Turbo in language proficiency exams, despite lagging behind in reading comprehension and knowledge-intensive tasks. This suggests that the capabilities that an LLM exhibits in a given language are not determined by its linguistic competence in this particular language, opening the doors to further improvements in low-resource LLMs as stronger English models become available.
The Latxa family of models, as well as our new pretraining corpora and evaluation datasets, are publicly available under open licenses at https://github.com/hitz-zentroa/latxa.
In the future, we plan to extend the training dataset by gathering quality content from diverse Basque sources such as publishers or media, as well as building evaluation datasets to assess aspects such as truthfulness or hallucinations. We also plan to further tune Latxa to follow instructions, which should improve the overall capabilities of our models.
This work has received support from the Basque Government, within the IKER-GAITU project. It has also been financed, within the ILENIA project, by the Ministry for Digital Transformation and Public Service and by the Recovery, Transformation and Resilience Plan – Funded by the European Union – NextGenerationEU, within the project with reference 2022/TL22/ 00215335. The development of the model used in-house GPU servers, and the final models were trained on CINECA's Leonardo supercomputer, within the EuroHPC Joint Undertaking (project EHPC-EXT-2023E01-013).



